First, if you’re not on Ravelry, you should be! It’s my favorite source for free and paid patterns alike, and you can filter your searches for super specific results (as well as a bunch more awesome features).
To the point, though, they’ve added another way to organize your favorites. It’s called “bundles,” and it looks like this:
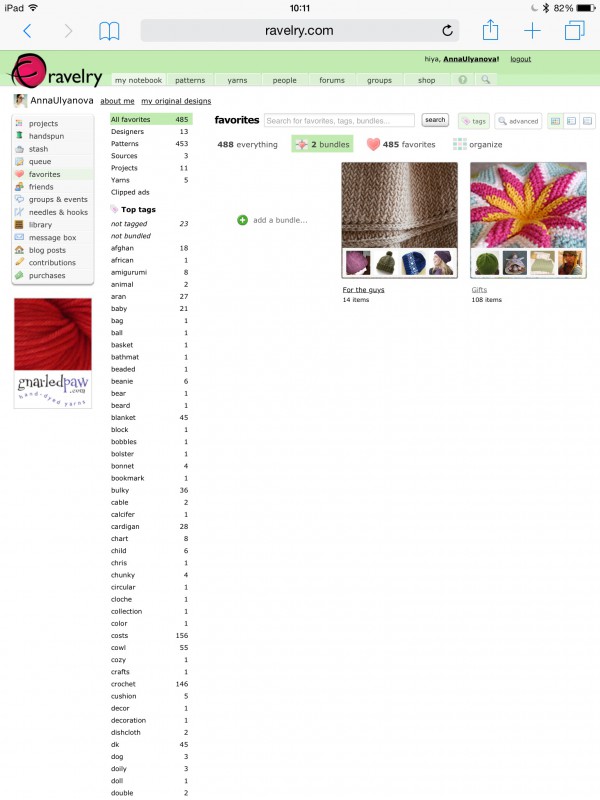
Looks kind of like Pinterest boards, don’t you think?
My question, however, is this: What kind of bundles do you make? As you can see I’ve got a bunch of tags already for organizational purposes, so I don’t know what bundles to make that wouldn’t be superfluous, but I really want to use them because they look so nice!
Do you alrady have bundles, and if so, what do you call them?


I’ve been avoiding the whole conversation about bundles because I didn’t really want to have to work out what it was all for. Lazy of me, but I already use most of Ravelry’s functions and I didn’t think I needed more. One day perhaps!
LikeLike
I totally understand — it’d be the greatest thing ever if Ravelry didn’t already have tags, etc. 🙂
LikeLike
Okay…nice conversation starter. I LOVE BUNDLE feature. In my mind I like to do sub-categories of things. I bundles allow me to extend my socks categories BEYOND the basics. I have them bundled in multiple categories and still use the regular tags too. Let’s take “Socks”– each bundle is listed by type of clothing >> then I use either knit technique or knit skill to separate them. Example of my bundles include: Socks– fairisle; Socks– textures; Socks– Lace. It just all depends. Then I can bundle Yarns by type or I also bundle patterns in Wishlist or holiday garment. I’m not into Pinterest, but Ravelry bundles feature provides more flexibility. Feel free to check out my Rav page: Fierybug08.
LikeLike
Those are great ideas, thanks so much! I love the idea of sub-categorizing items that way (especially when I have so many favorites). I’ll add you as a friend!
LikeLiked by 1 person
I have to admit that I have only been on Ravelry a couple of times. I only have 1 pattern in my library (the Gentille Cowl) and went there yesterday to download a fix for the pattern. But other than that I haven’t had time to explore. I really need to do that. So, I have no idea what the bundles are about or tags or anything. Another thing I will have to investigate.
LikeLike
Oooooooh I hope you like it when you have time to explore! When I first found out about it I spent DAYS looking through almost every free crochet pattern and was inspired enough to last me for years, hehe.
LikeLike
Is the bundles for library or favourites or both?
Must look.
LikeLike
I think just favorites, but I didn’t look in the Library to see if it was there too so I’m not actually sure!
LikeLike
I’ve always tagged my items with the year I made them so I can see how I do one year to the next. I love being able to make notes on the write ups I do on projects I’ve made so that I can go and look to see if there were problems with the pattern, or if I had to change the size hook I used, and that sort of thing. Honestly, I haven’t noticed the bundling feature.
LikeLike
I made 3 bundles so far: one called nephews, where I put all the patterns I can make to my beloved small humans :), other called purchased, so I don’t forget the patterns I purchased and finally one called simply crochet with the patterns from the magazine I want to make.
LikeLike
A really great way to look at it is to think of the ‘Bundles’ as filing cabinets. So let’s say you make a bundle called ‘Women’s Clothing’. And then think of ‘Tags’ as the folders within that filing cabinet. So you could have a ‘folder’ (tag) for Sweaters, Cardigans, Spring Tops, or any other folder/tag that would help you to organize your bundle to make it easier to find what you are looking for.
It’s not such a big deal whether you use the Bundles and Tags when you only have a handful of Favorites. However, if you have a large number of patterns, notes, yarns, etc… favorited, then it really does become a much more ideal way to handle off them.
Hope this can help someone!!
LikeLike